
APM steht für Application Performance Management und erlaubt es als Teil der Observability, die eigene Anwendung genauer zu durchleuchten. Wie lange dauern bestimmte SQL-Abfragen? Welche Microservices oder Datenbanken werden innerhalb eines HTTP Requests abgefragt? Welcher Teil eines HTTP Requests ist der eigentliche Flaschenhals und weist die längste Antwortzeit auf? Um diese Fragen zu beantworten, reicht es nicht, Logs oder Metriken zu betrachten, sondern man muss sich die Laufzeit einzelner Methoden oder Aufrufe innerhalb der eigenen Anwendung ansehen. Hier kommt APM ins Spiel.
APM als Säule der Observability
APM gehört zum Tracing, das neben Logs und Metriken als eine der drei Säulen der Observability gilt. Dabei geht es allerdings nicht um die Daten selbst oder die Art der Datengenerierung, sondern allein um die Möglichkeit, aus vielen Signalen (Logs, Metriken, Traces, Monitoring, Health Checks) diejenigen herauszufiltern, die auf eine mögliche Einschränkung eines eigenen oder fremden Service wie Antwortzeit oder Verfügbarkeit hindeuten. Einzelne Bereiche der Observability sollten nicht isoliert betrachtet und idealerweise auch nicht mit unterschiedlichen Tools bearbeitet werden, damit man nicht nachts um drei Uhr mit mehreren Browsertabs und manueller Korrelation bei einem Ausfall eingreifen muss. Eine Kerneigenschaft des APM ist die Darstellung der Laufzeit von Komponenten der eigenen Anwendung. Die zwei wichtigsten Begriffe sind hier Transaction und Span. Eine Transaction ist eine systemübergreifende Zusammenfassung einzelner Spans, welche die Laufzeit konkreter Methoden oder Aktionen innerhalb eines Systems zusammenfassen. Eine Transaction kann sich über mehrere Systeme ziehen und beginnt bei einer Webanwendung im besten Fall im Browser des Users (Abb. 1).
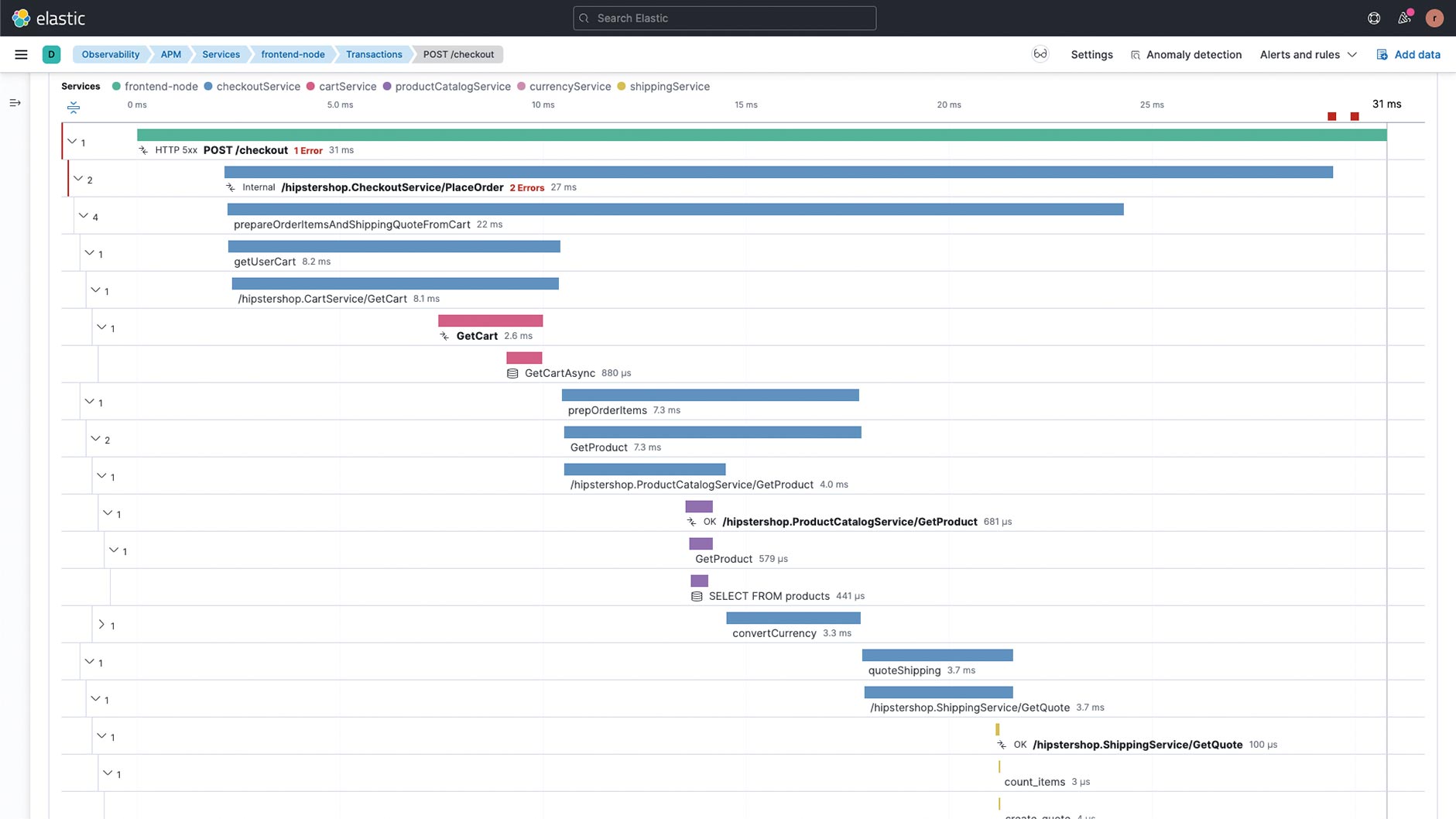
Abb. 1: Transaction über mehrere Systemgrenzen (farbig gekennzeichnet)
Instrumentierung innerhalb der JVM
Bei APM-Agenten liegt der Fall etwas anders als bei Logging und Metriken, da sie in die Anwendung hineinschauen müssen und diese unter Umständen auch verändern. Bugs in diesen Agenten sind gefährlich und können sich auf die Anwendung auswirken – unabhängig von der Programmiersprache. Java hat im Gegensatz zu vielen anderen Sprachen eine standardisierte Schnittstelle zur Instrumentierung. Der durch Kompilierung erstellte Bytecode kann verändert werden und die Anwendung kann mit diesen Änderungen weiterlaufen. Um diese Veränderung so einfach wie möglich zu implementieren, gibt es Bibliotheken wie ASM oder Byte Buddy, mit denen Methodenaufrufe abgefangen werden können, um beispielsweise die Laufzeit zu messen. Wenn ich als Entwickler eines Agenten also alle Aufrufe des in der JVM eingebauten HTTP-Clients abfange und die Laufzeit sowie den Endpunkt als Teil eines Spans logge, kann ich danach einfach im APM UI sehen, wie viel Zeit diese Anfrage benötigt und ob lokales Request Caching beim Einhalten möglicher SLAs hilft. Durch Aktivieren des Agenten darf kein oder nur geringer Einfluss auf die Geschwindigkeit der Anwendung genommen werden (Overhead). Das Gleiche gilt für die Garbage Collection. Beides lässt sich nicht völlig verhindern, jedoch stark reduzieren.
Regelmäßig News zur Konferenz und der JAX-Community erhalten Stay tuned
Der Zeitpunkt der Instrumentierung ist unterschiedlich. Die bekannteste und beliebteste Variante ist das Setzen des Agents als Parameter beim Starten der JVM:
java -javaagent:/path/to/apm-agent.jar -jar my-application.jarDieser Aufruf führt die Instrumentierung aus, bevor der eigentliche Code geladen wird. Alternativ kann die Instrumentierung auch bei einer bereits laufenden JVM stattfinden.
Doch was genau bedeutet Instrumentierung eigentlich? Die Laufzeit von Methoden kann nur gemessen werden, wenn diese Methoden abgefangen werden und Code des Agenten um den eigentlichen Code herum ausgeführt wird – zum Beispiel das Anlegen eines Spans oder einer Transaction, wenn ein HTTP Request abgeschickt wird. Dieser Ansatz ist aus der aspektorientierten Programmierung bekannt. Eine Voraussetzung muss gegeben sein: Der jeweilige APM-Agent muss die Methode inklusive Signatur kennen, die instrumentiert wird. Für Java Servlets ist zum Beispiel die Methode service(HttpServletRequest req, HttpServletResponse resp) im Interface HttpServlet die wichtigste Methode, um jeden HTTP-Aufruf zu überwachen, unabhängig vom Pfad oder der HTTP-Methode. Das bedeutet gleichzeitig, dass bei einer Änderung der Methodendeklaration der Agent ebenfalls angepasst werden muss. Und hier liegt eines der größten Probleme mit dieser Form der Überwachung: Es muss sichergestellt sein, dass sowohl möglichst viele Frameworks (Spring Boot, JAX-RS, Grails, WildFly, Jetty etc.) und deren Methoden instrumentiert werden, als auch ständig überprüft wird, ob die Instrumentierung bei einem neuen Release noch funktioniert, besonders bei Major Releases. Das ist eine der großen Maintenance-Aufgaben bei der Entwicklung von APM-Agenten. Während es einige Standards im Java-Bereich gibt, die einfach zu instrumentieren sind, wie Servlets, JDBC oder JAX-RS, gibt es ebenfalls eine Menge Frameworks, die keinen solchen Standards folgen, wie beispielsweise Netty. Das heißt auch, dass jeder Agent, dessen Instrumentierung eines Frameworks nicht funktioniert hat, weil eventuell Methoden aus einer anderen Major-Version mit anderer Signatur existieren, sicherstellen muss, dass dies kein Problem darstellt.
Bisher haben wir nur APM Agents im Kontext von Java Agents erwähnt; es gibt aber noch weitere Anwendungsfälle. Ganz aktuell hat das AWS-Corretto-Team um Volker Simonis einen Agent zum Patchen der Log4Shell-Sicherheitslücke entwickelt [1]. Der Agent verhindert das Sicherheitsproblem der Remote Code Execution bei einer bereits laufenden JVM. Ein anderer Use Case sind Agents, die Sicherheitsfeatures wie das automatische Setzen von HTTP Headern oder WAF-Funktionalität bereitstellen.
Agents und ihre Features
Der bekannteste Standard in der Observability-Welt ist OpenTelemetry [2]. Die Idee von OpenTelemetry ist, den einen, herstellerneutralen, universellen Standard zur Verfügung zu stellen, den alle verwenden, unabhängig von der Programmiersprache. Mit dem OpenTelemetry Agent gibt es einen JVM Agent, den viele Observability-Anbieter als eigene Distribution veröffentlichen, wie zum Beispiel Lightstep oder Honeycomb. Dieser kommt bereits mit einigen Instrumentierungen für bekannte Frameworks [3].
Eine weitere Standardisierung in Zeiten von Microservices und der Möglichkeit, einen Request vom Laden der Webseite im Browser bis zur SQL-Query zu identifizieren, ist das Distributed Tracing. Um Distributed Tracing zwischen verschiedenen Programmiersprachen und Umgebungen zu implementieren, existiert die OpenTracing-Spezifikation und -Implementierung. Viele APM Agents folgen dieser Spezifikation, um Kompatibilität sicherzustellen, unter anderem Lightstep, Instana, Elastic APM, Apache Skywalking und Datadog.
Vor OpenTelemetry gab es einige wenige Agents, die aus JVM-Sicht eigentlich gar keine waren, weil sie keinerlei Instrumentierung vorgenommen, sondern lediglich Interfaces in bestimmten Frameworks implementiert haben, um Monitoringdaten auszulesen. Ich gehe davon aus, dass es über kurz oder lang nur noch Agents geben wird, die auf dem OpenTelemetry Agent basieren, und dass die Alleinstellungsmerkmale nicht im Sammeln der Daten, sondern ausschließlich in der Auswertung liegen.
Elastic APM Agent
Wenn es einen OpenTelemetry Agent gibt, wieso gibt es dann zum Beispiel auch einen Elastic-APM-spezifischen Agent? Zum einen gibt es eben doch mehr Features als einen universellen Standard. Beispiel: das Erfassen interner JVM-Metriken (Speicherverbrauch, Garbage-Collection-Statistiken) oder auch das Auffinden langsam ausführender Methoden ohne das Wissen um konkrete Methoden oder Code mit Hilfe des async-profilers [4] – eine Technologie, die bei Datadog, Elastic APM oder Pyroscope [5] verwendet wird. Des Weiteren existieren eine Menge Agenten bereits länger als die OpenTelemetry-Implementierung und bringen mehr Unterstützung für bestimmte Frameworks mit, die erst in den OpenTelemetry-Agenten portiert werden müssen.
Der Elastic Agent bietet zudem ein weiteres sehr interessantes Feature, und zwar das programmatische Konfigurieren des Agent anstatt der Verwendung des JVM-Agent-Mechanismus als Parameter beim Starten der JVM. Das bedeutet, man bindet den Agent als Dependency in den Code ein, und versucht die folgende Zeile Code beim Start der Anwendung so früh wie möglich auszuführen:
ElasticApmAttacher.attach();Jetzt geschieht prinzipiell dasselbe wie bei der Agent-spezifischen Konfiguration: Der Agent attacht sich selbst an den laufenden Code. Diese Art der Einrichtung hat einen großen Vorteil: Die Dependency ist bereits Teil des Deployments und muss nicht als Teil des Build-Prozesses oder der Container-Image-Erstellung heruntergeladen werden. Gleichzeitig ist der Entwickler für das fortlaufende Aktualisieren verantwortlich.
Bisher ungeklärt ist die Frage, was ein APM Agent mit den erhobenen Daten eigentlich machen soll. Im Fall von Elastic APM werden diese an einen APM-Server geschickt, der sie wiederum im nächsten Schritt in einem Elasticsearch Cluster speichert. Der APM-Server kommuniziert nicht nur mit den anderen Elastic APM Agents (Node, Ruby, PHP, Go, iOS, .NET, Python), sondern kann auch Daten puffern und als Middleware für Source Mapping bei JavaScript-Anwendungen agieren.
Wie bereits erwähnt, liegt der Mehrwert weniger im Sammeln als im Auswerten von Daten. Im Fall von Elastic APM ist das unter anderem die Integration mit Machine Learning, genauer der Time Series Anomaly Detection, um automatisiert Laufzeiten von Transaktionen zu erkennen, die im Vergleich zu vorher gemessenen Ergebnissen überdurchschnittlich lange brauchen, dem automatischen Annotieren von Deployments im APM UI oder auch der Korrelation von plötzlich auftretenden Transaktionslatenzen und Fehlerraten in allen von der Anwendung generierten Logs. So wird sichergestellt, dass die Grenzen zwischen den anfangs erwähnten Observability-Säulen nicht existieren.
Programmatische Spans und Transactions
Nicht jeder Entwickler möchte ein eigenes APM-Agent-Plug-in schreiben, damit die eigene Java-Anwendung Spans und Transactions innerhalb der eigenen Geschäftslogik verwendet. Ein alle 30 Sekunden laufender Job im Hintergrund sollte als eigene Transaktion und jede der darin aufgerufenen Methoden als eigener Span konfiguriert werden. Hier gibt es zwei Möglichkeiten der Konfiguration. Entweder werden die Methodennamen über die Agentenkonfiguration angegeben oder man wählt die programmatische Möglichkeit. Ein Beispiel innerhalb von Spring Boot zeigt Listing 1.
@Component
public class MyTask {
@CaptureTransaction
@Scheduled(fixedDelay = 30000)
public void check() {
runFirst();
runSecond();
}
@CaptureSpan
public void runFirst() {
}
@CaptureSpan
public void runSecond() {
}
}
Die Annotation @CaptureTransaction legt eine neue Transaktion an und innerhalb dieser Transaktion werden die beiden Spans für die Methoden via @CaptureSpan angelegt. Sowohl Transaktion als auch Spans können mit einem eigenen Namen konfiguriert werden, der im UI einfacher identifiziert werden kann. Unter [6] gibt es ein GitHub Repository, das sowohl die Instrumentierung des Java-HTTP-Clients zeigt als auch das Verwenden von programmatischen Transaktionen und Spans im eigenen Java-Code.
Elastic APM Log Correlation
Wie erwähnt, ist es sinnvoll, Logs, Metriken und Traces miteinander zu verbinden. Wie aber kann eine bestimmte Logzeile mit einer bestimmten Transaktion verbunden werden? In Elastic APM heißt dieses Feature Log Correlation. Der erste (optionale) Schritt ist, Logdateien ins JSON-Format zu überführen. Das macht es wesentlich einfacher, weitere Felder zu den Logdaten hinzuzufügen. Eben diese Felder werden für die Korrelation benötigt. Wenn man im Agent die Option log_ecs_reformatting verwendet, werden im sogenannten MDC der jeweiligen Logger-Implementierung die Felder transaction.id, trace.id und error.id hinzugefügt, nach denen dann sowohl in Transactions und Spans als auch in einzelnen Lognachrichten gesucht werden kann. So können Lognachrichten unterschiedlichster Services miteinander korreliert und durchsucht werden; Logmeldungen eines Service sind einer konkreten eingehenden HTTP-Anfrage zuzuordnen.
Automatische Instrumentierung mit K8s
Will man Container mit Java-Anwendungen unter Kubernetes instrumentieren, kann man jederzeit die verwendeten Images/Pod-Konfigurationen anpassen und innerhalb dieser den Agent konfigurieren sowie APM-Konfigurationen einstellen, zum Beispiel APM-Endpunkte, API-Token (zum Beispiel via HashiCorp Vault [7]) oder die erwähnte Log Correlation. Es gibt eine weitere Möglichkeit, und zwar die Verwendung eines Init-Containers, der vor den eigentlichen Anwendungscontainern in einem Pod ausgeführt wird [8]. Dieser Container konfiguriert Umgebungsvariablen, die dann beim Starten des regulären Containers ausgelesen werden und somit zusätzlich den passenden JVM-Agenten starten [9]. Dieser Ansatz kann sinnvoll sein, wenn man keine Kontrolle über die erstellten Container hat oder sicherstellen möchte, dass ein Agent in einer bestimmten Version für alle Java-Anwendungen läuft.

Distributed Tracing mit RUM
In Zeiten von Microservices und APIs ist es in vielen Systemarchitekturen wahrscheinlich, dass ein einzelner Aufruf eines Anwenders sich zu mehreren Aufrufen in der internen Architektur multiplext und mehrere Services abgefragt werden. Hier ist es besonders wichtig, verfolgen zu können, wie ein initialer Request durch die unterschiedlichen Services weitergereicht und verändert wird. Eine Transaktion kann mehrere Spans haben, die in unterschiedlichen Systemen auftreten, unter Umständen auch gleichzeitig. Hier kommt Distributed Tracing mit Hilfe von Trace IDs ins Spiel, die durch alle Requests hindurch – zum Beispiel mit Hilfe von HTTP-Headern – an die jeweiligen Spans angehängt werden und somit durch den Lebenszyklus des initialen Request rückverfolgbar sind. Ein weiterer Vorteil von Distributed Tracing ist die Möglichkeit, aus diesen Daten eine Service Map zu erstellen, da man weiß, welche Services miteinander kommunizieren (Abb. 2).
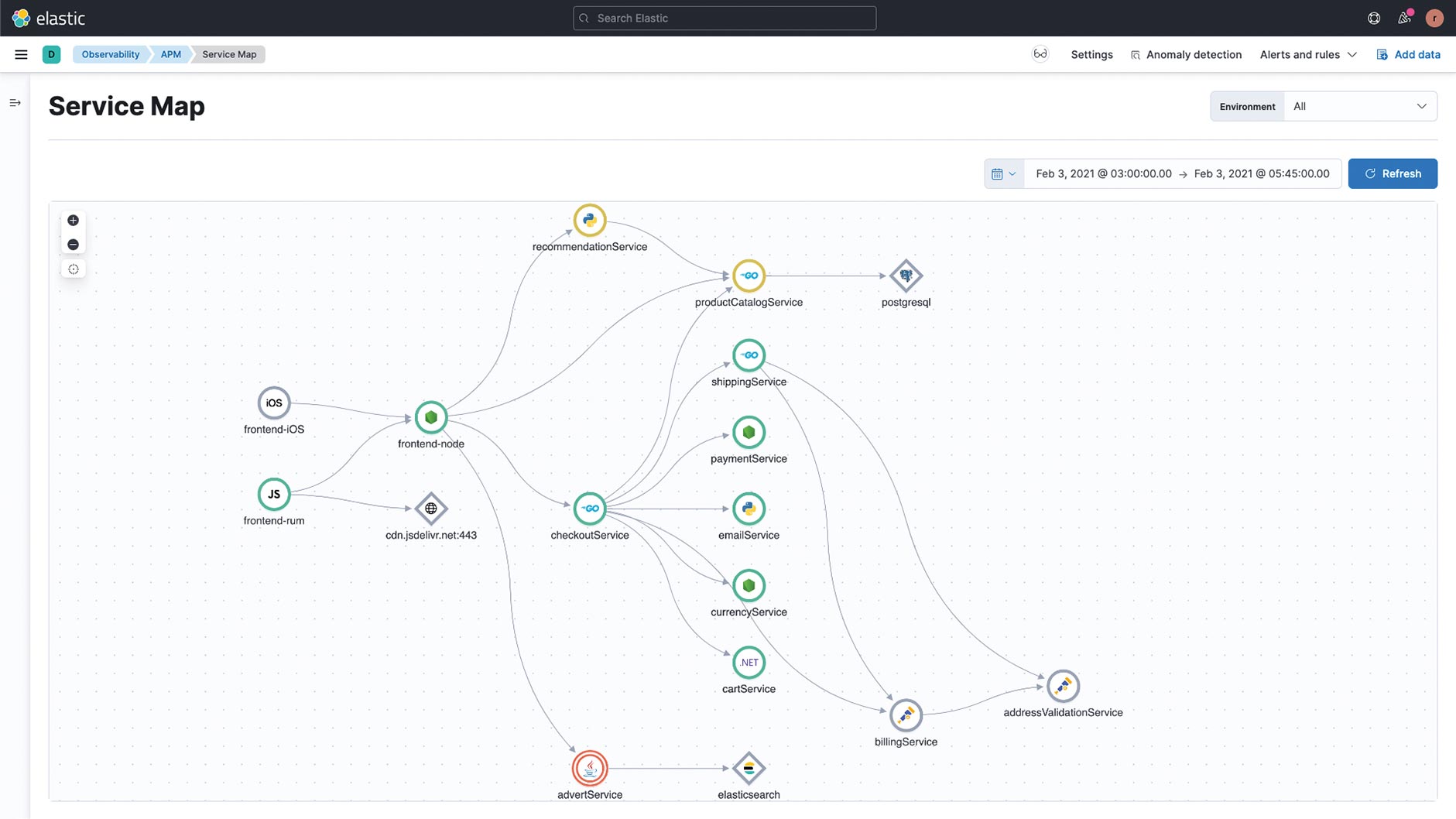
Abb. 2: Service Map, um Kommunikationsflüsse einzelner Komponenten zu visualisieren
Bei der Entwicklung von Webanwendungen ist es ebenfalls nicht ausreichend, erst an den eigenen Systemgrenzen mit dem Anlegen von Transactions und Spans zu beginnen, da man sonst keinen Überblick über die komplette Performance der eigenen Anwendung hat. Wie lange dauert das Aufbauen der Verbindung im Browser zum Webserver? Ist die Latenz hier eventuell so hoch, dass es irrelevant ist, 50 ms bei einer komplexen SQL-Query zu sparen? Um dieses Problem anzugehen, gibt es das Real User Monitoring, kurz RUM. Zum einen können Transaktionen an der richtigen Stelle begonnen werden, zum anderen werden auch Browserereignisse geloggt, um festzustellen, wie lange das initiale Rendern der Seite braucht, sodass der Anwender mit der Anwendung interagieren kann (Abb. 3).
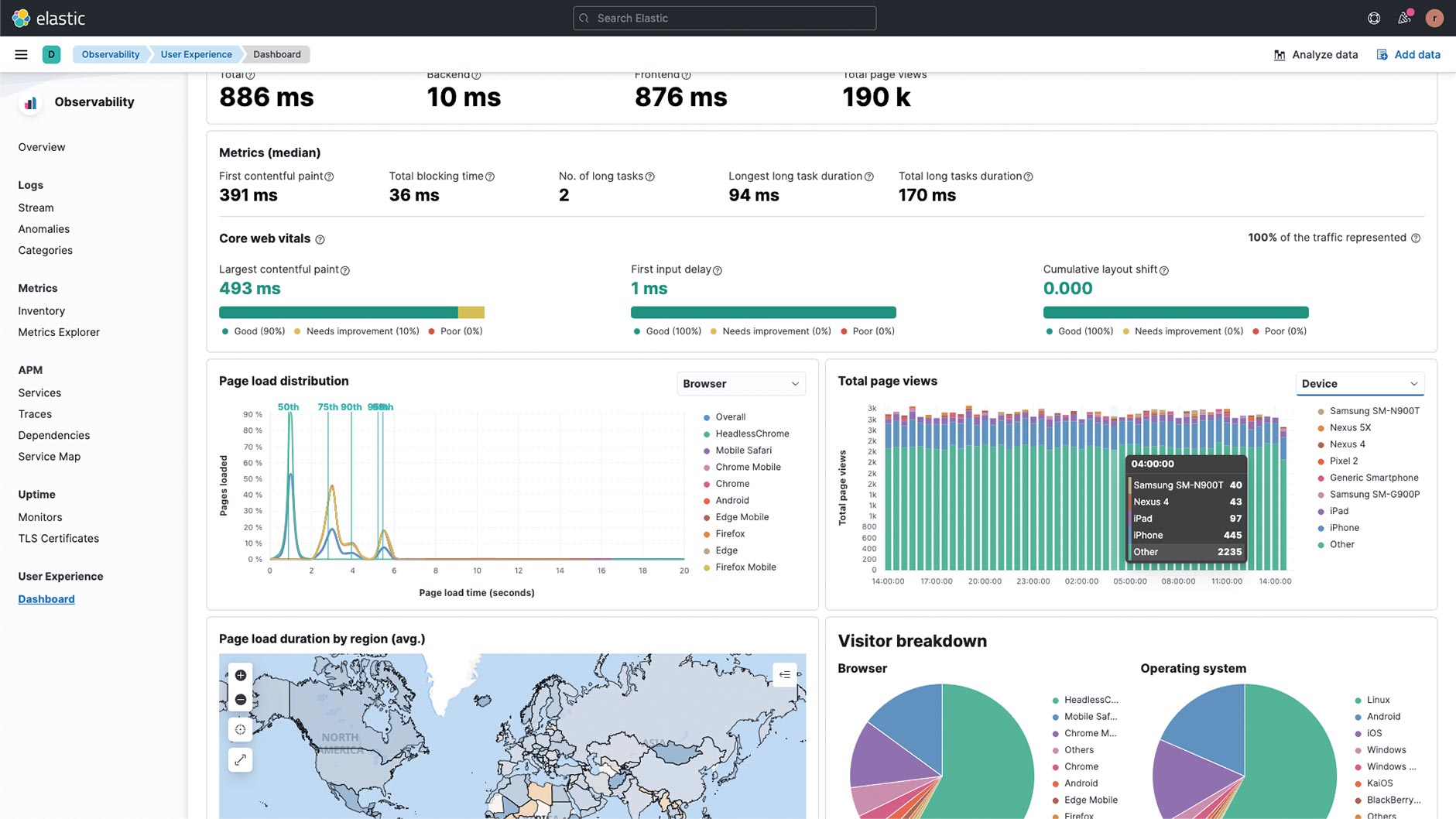
Abb. 3: RUM-Dashboard mit Ladezeiten und Browserstatistiken
APM in der Zukunft
Das Bedürfnis, für Anwendungen eine Art Röntgengerät zu bekommen, wird in Zukunft noch zunehmen – vielleicht werden sich die Methoden etwas ändern. Zeit für einen kleinen Ausblick. In den vergangenen Jahren ist eine neue Art von Agents auf den Markt gekommen, die eine neue, sprachunabhängige Technologie verwenden: eBPF. Mit Hilfe von eBPF kann man Programme im Kernelspace laufen lassen, ohne den Kernel zu verändern oder ein Linux-Kernel-Modul laden zu müssen. Alle eBPF-Programme laufen innerhalb einer Sandbox, sodass das Betriebssystem Stabilität und Geschwindigkeit garantiert. Da eBPF Syscalls überwachen kann, ist es ein idealer Einstiegspunkt für jegliche Observability-Software. Der weitaus wichtigere Teil ist allerdings die Möglichkeit, diese Syscalls auf Methodenaufrufe in die jeweilige Programmiersprache des überwachten Programms zu übersetzen. eBPF-basierte Profiler haben generell einen geringen Overhead, da sie sehr tief im System verankert sind. Des Weiteren müssen keine Deployments angepasst werden, da diese Profiler auch innerhalb eines Kubernetes-Clusters für alle Pods konfiguriert werden können. Beispiele für diese Art von Profiler sind prodfiler [10] von Elastic, Pixie [11], Parca [12] oder Cilium Hubble [13].
Ein weiteres neues Themenfeld ist das Überwachen auf Serverless-Plattformen. Hier braucht man etwas andere Lösungen, da nicht garantiert ist, dass nach dem Verarbeiten einer Anfrage noch Rechenkapazität zur Verfügung gestellt wird. Methoden wie etwa Spans und Traces als Batch zu sammeln und periodisch an den APM-Server zu verschicken, funktionieren hier also nicht. Für AWS Lambda steht mit opentelemetry-lambda [14] ein eigenes GitHub-Projekt zur Verfügung. Die grundlegende Idee ist ein sogenannter Lambda-Layer, der diese Observability-Aufgaben übernimmt. Wenn man also in diese Art von Plattformen eintaucht, sollte man sicherstellen, dass die eigene Observability-Plattform diese Technologien unterstützt.
Ein weiterer wichtiger Baustein abseits vom Sammeln und Auswerten der Livedaten ist der Trend zu Shift Left – nicht nur in der Security. Hier bietet JfrUnit [15] von Gunnar Morning einen interessanten Ansatz aus dem Umfeld des Java Flight Recorders. Als Teil des Unit Testings werden JFR Events herangezogen, um bestimmte Constraints wie Garbage Collection, erhöhte Memory Allocation oder I/O bereits in Tests festzustellen und vor dem eigentlichen Deployment zu korrigieren.
Regelmäßig News zur Konferenz und der JAX-Community erhalten Stay tuned
Schlusswort
Wie überall, so ist auch in der Welt der JVM Agents für APM nicht alles rosig. Einige Agents unterstützen zum Beispiel nur die bekanntesten Web-Frameworks wie Spring oder Spring Boot bzw. auch innerhalb eines Frameworks nur synchrones Request Processing. Es gilt daher, anfangs in Ruhe mögliche Agents zu testen. Fast alle Agents sind Open Source, sodass man im Fall der Fälle auch ein eigenes Plug-in schreiben kann. Je nach Sicherheitseinstellungen der Plattform, auf der Services betrieben werden, ist es eventuell nicht erlaubt, einen Agent programmatisch an den Java-Prozess anzuhängen – zum Beispiel ist mir das bei der Digital-Ocean-Apps-Plattform, einem PaaS, nicht gelungen. Der -javaagent-Parameter innerhalb des Docker Image hat hingegen einwandfrei funktioniert.
Ein weiteres Thema, das man in den aktuellen Java-Trends wahrscheinlich schon entdeckt hat, ist GraalVM. Falls mit Hilfe der GraalVM die Anwendungen in native Binaries umgewandelt werden, existiert der Mechanismus zum Anhängen von Java Agents nicht. Das heißt nicht, dass keinerlei Instrumentierung möglich ist. Die programmatische Erstellung von Spans und Traces könnte allerdings bei einigen APM-Lösungen noch funktionieren, die nicht auf reines Bytecode Enhancement setzen. Da viele bekanntere Frameworks wie Spring und Quarkus inzwischen native Extensions und Module haben, um möglichst einfache Binaries zu erstellen, erwarte ich in den nächsten Monaten, dass auch die APM-Plattformen nachziehen werden. Quarkus hat bereits Support für OpenTracing und DataDog im native Mode.
Um es noch einmal abschließend zu wiederholen: Observability ersetzt kein Monitoring und APM ersetzt kein effizientes Entwickeln performanter Software. Viele Probleme können durch Testing, Reviews oder Pair Programming sehr viel früher im Lebenszyklus der Software gefunden werden und sind dann weitaus ökonomischer zu fixen. Wesentlich komplizierter ist das bereits bei Distributed Tracing und dessen Intersystemkommunikation, um mögliche Bottlenecks vor dem Produktionsbetrieb zu identifizieren. Nichtsdestoweniger ist ein so tiefer Einblick in die selbstgeschriebene Software, wie APM ihn bietet, von Vorteil und sollte auch genutzt werden, wenn der zusätzliche Aufwand der initialen Einrichtung einmal erledigt ist.
Links & Literatur
[1] https://github.com/corretto/hotpatch-for-apache-log4j2
[4] https://github.com/jvm-profiling-tools/async-profiler
[6] https://github.com/spinscale/observability-java-samples
[7] https://www.vaultproject.io/
[8] https://kubernetes.io/docs/concepts/workloads/pods/init-containers/
[9] https://www.elastic.co/blog/using-elastic-apm-java-agent-on-kubernetes-k8s
[11] https://px.dev
[13] https://github.com/cilium/hubble
[14] https://github.com/open-telemetry/opentelemetry-lambda
[15] https://github.com/moditect/jfrunit
Mehr zum Thema auf der W-JAX & JAX:
● Session: Softwareentwicklung: Wir sind innovativ!
● Session: Flutter für Java-Entwickler: Web-, Mobile- und Desktop-Frontends mit einer Codebasis?




